Table of contents
- Main idea
- The WordPress.org Plugins Directory
- Scanner to detect vulnerable plugins
- Debugging WP updates with Burp
- Publishing WordPress plugin PoC
- How to defend yourself
- Bug Bounty hunting
Main idea
I recently did a regular secure code review of one WordPress instance and noticed a new internally developed plugin. It occurred to me that if an attacker would be able to impersonate the plugins’ slug and upload a malicious version to the WordPress Plugin Directory, we might see an update notification if the SVN version is bumped to a higher one than is used.
That would introduce the “Confused deputy problem” attack scenario, where the privileged user, instructed to update all plugins regularly, inadvertently infects the instance with malware.
One could argue that the confused deputy shouldn’t blindly update plugins without checking the changelog first, but to be honest, the updates are released so often it quickly becomes monotonous. And we shouldn’t put them in that position in the first place, as it’s security through obscurity, believing that an outside attacker can’t figure out the plugin’s name.
To confirm the hypothesis, I began to research if it’s, in fact, a possible attack vector and how widespread it is.
The WordPress.org Plugins Directory
WordPress.org offers free hosting to anyone who wishes to develop a plugin. All code in the directory should be as secure as possible, but security is the ultimate responsibility of the plugin developer.
The WordPress.org plugins directory is the easiest way for potential users to download and install any plugin. Once a new plugin is approved, a developer gets access to an (SVN) Subversion Repository. The SVN repository is a release repository, not a development one. All commits, code, or readme files, will trigger a regeneration of the zip files associated with the plugin.
WordPress’ integration with the plugin directory means the user can update the plugin in a couple of clicks. Users are alerted to updates when the plugin version in SVN increases.
In theory, anyone following the guidelines and passing the review process can upload the plugin and distribute the malicious version later. Unfortunately, while reading the developer documentation, I found the following info:
Why is my submission failing saying my plugin name already exists? You’re trying to use a plugin with a permalink that exists outside WordPress.org and has a significant user base. It’s important to understand that the way the plugin update API works is that it compares the plugin folder name (i.e. the permalink) to every plugin it has hosted on WordPress.org. If there’s a match, then it checks for updates and users are prompted to upgrade. When that happens, users of the ‘original’ plugin (the one we don’t host) would upgrade to the one from WordPress.org and, if that isn’t what you actually wanted to do, you could break their sites. Sometimes this situation develops when a company or person releases their plugin privately (via Github for example) and decides they want to re-release it on WordPress.org. In those cases, we recommend you email us and we’ll walk you through how to get past the error.
Implying that WordPress’ Security team is internally tracking all the unclaimed plugin names used in the wild, number of installations, and there is some magic threshold value preventing a large-scale supply chain attack. But it also validates the assumption that the attack vector is indeed possible.
Theme approval process
Most business websites using WordPress have a custom theme, and the slug name is almost always in the HTML source code to load JS/CSS files from the theme’s asset directory. Detecting the theme slug and taking over the unclaimed ones would be the easiest way.
WordPress Theme Directory does have a rigorous Theme Review Process & Theme Review Requirements, to ensure quality and security. New themes are generally put to a higher standard to attract new users.
It would be hard for me to develop a frontend appealing to a general audience and pass the review, so I decided not to worry about them.
Plugin approval process
On the other hand, it’s impossible to detect most plugins via a passive check, and it will be tough to create a custom wordlist. But the review process for WordPress Plugin Directory is not that strict, and the guidelines are relatively simple.
While reading the docs, I was mainly interested in the restrictions for plugin names. Being already familiar with WordPress, I knew that the slug name could only contain lowercase alphanumeric characters divided by dash, but I also learned there are more restrictions:
Plugins must respect trademarks, copyrights, and project names. Names cannot be “reserved” for future use or to protect brands. The use of trademarks or other projects as the sole or initial term of a plugin slug is prohibited unless proof of legal ownership/representation can be confirmed. This policy extends to plugin slugs, and we will not permit a slug to begin with another product’s term.
That threw me off because apparently, there is a check for trademarked brands, which will protect most companies and prohibit uploading unclaimed plugins (assuming they use their company name as a prefix for internal plugins). I didn’t want to give up yet, so I started digging around, and it turns out the WordPress team is a fan of transparency, and the whole approval process is automated and, most importantly, fully open-sourced.
By reviewing the [class-upload-handler.php](https://meta.trac.wordpress.org/browser/sites/trunk/wordpress.org/public_html/wp-content/plugins/plugin-directory/shortcodes/class-upload-handler.php) checks, we can see a couple of essential functions:
process_upload()- Determine the plugin slug based on the name of the plugin in the main plugin file. (alphanumeric and dash)
88 $this->plugin_slug = remove_accents( $this->plugin['Name'] );
89 $this->plugin_slug = preg_replace( '/[^a-z0-9 _.-]/i', '', $this->plugin_slug );
90 $this->plugin_slug = str_replace( '_', '-', $this->plugin_slug );
91 $this->plugin_slug = sanitize_title_with_dashes( $this->plugin_slug );
has_reserved_slug()- Make sure it doesn’t use a slug deemed not to be used by the public. (common WordPress paths like wp-admin are not allowed)
388 public function has_reserved_slug() {
389 $reserved_slugs = array(
390 // Plugin Directory URL parameters.
391 'about',
392 'admin',
393 'browse',
394 'category',
395 'developers',
396 'developer',
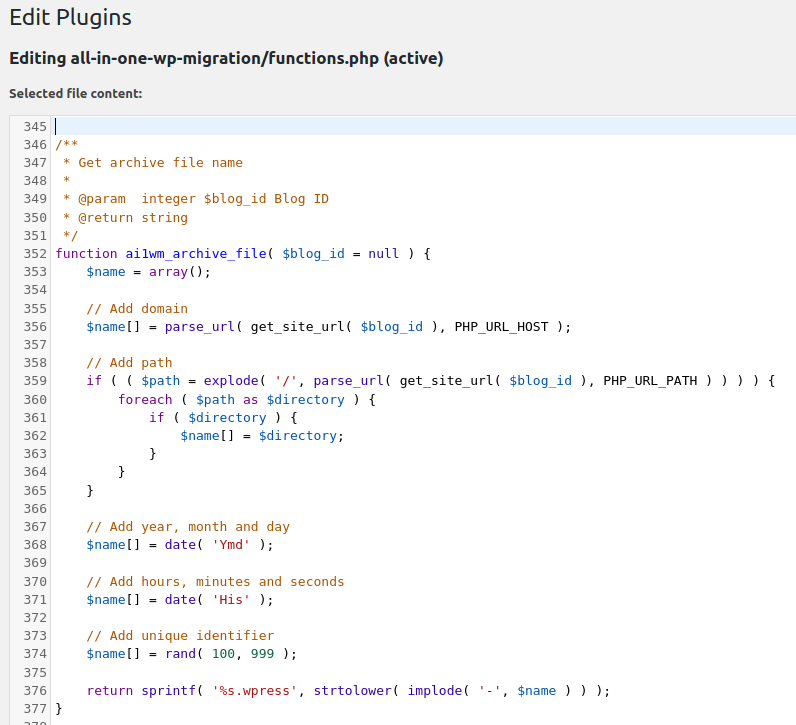
has_trademarked_slug()- Make sure it doesn’t use a TRADEMARK protected slug. (trademarked company names are not allowed)
430 public function has_trademarked_slug() {
431 $trademarked_slugs = array(
432 'adobe-',
433 'adsense-',
434 'advanced-custom-fields-',
435 'adwords-',
436 'akismet-',
437 'all-in-one-wp-migration',
438 'amazon-',
439 'android-',
440 'apple-',
441 'applenews-',
442 'aws-',
Surprisingly, big enough (FAANG) style companies can request to add themselves to the list ($trademarked_slugs) of prohibited terms, and any uploads of plugins containing that name will automatically fail. Most importantly, there is also the check preventing uploads using popular plugin names already used in the wild:
231 if ( function_exists( 'wporg_stats_get_plugin_name_install_count' ) ) {
232 $installs = wporg_stats_get_plugin_name_install_count( $this->plugin['Name'] );
233
234 if ( $installs && $installs->count >= 100 ) {
235 $error = __( 'Error: That plugin name is already in use.', 'wporg-plugins' );
In conclusion, the WordPress Plugin Confusion attack against internally developed plugins on business websites is indeed possible. Still, the security mechanism prevents large-scale supply chain attacks against unclaimed plugins installed on more than 100 websites.
Scanner to detect vulnerable plugins
I wrote a simple tool wp_update_confusion.py, which will passively detect any plugins from the front page response and check if the plugin name contains only the allowed characters. It then pings the WordPress SVN to verify if the slug is already claimed or not.
While scanning websites of HackerOne public bug bounty programs, it was reporting a ton of false positives. I quickly realized that it would be impossible to get any meaningful output without a database of paid WordPress plugins. And building one by myself would require a significant amount of time.
Instead of reinventing the wheel and knowing from the review process code that the WordPress team already has the data, I started looking around the website. Every plugin has an “Advanced View” tab, where one can see various graphs, such as active versions, downloads per day, install growth, etc.
Poking around the API revealed one publicly available endpoint, which in fact, returns all_time number of downloads for any unclaimed plugin slug:
https://api.wordpress.org/stats/plugin/1.0/downloads.php?slug={plugin_name}&historical_summary=1
In the end, having all the information needed to verify if we could take over the plugin resulted in much better results. Although I didn’t implement a brute-force option, which would be the best way how to earn bug bounties, so right now, it is only capable of detecting low hanging fruits :)
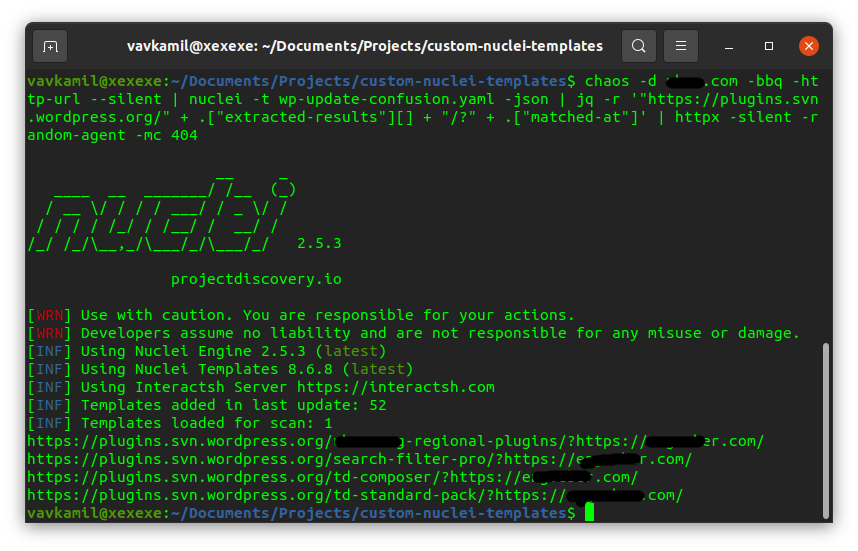
The way it works is:
1) Query the front-page and find all the plugins re.findall("wp-content/plugins/(.*?)/", html)
2) Check if the slug is allowed
3) Check if the slug is present in the SVN registry
4) Check if the slug is installed on more than 100 websites
5) Profit?
Debugging WP updates with Burp
The next step was to debug how the plugin mechanism exactly works. The easiest solution would be to review the code, but since I’m not that familiar with PHP, a black-box style test sounded like a better idea.
Since I like Burp Suite a lot, I decided to intercept the requests between the website and wordpress.org API via its proxy. Running the WordPress in Docker container is easy, but installing the SSL cert and routing all the external traffic via Burp wasn’t that simple.
After a lot of debugging, I came up with the following:
1) Configure Proxy Listener to listen on all interfaces
2) Add IP address of the Proxy as extra_hosts in docker-compose.yml
3) Run docker and install the WordPress via wp-cli
4) Download & install Burp Suite certificate
#!/usr/bin/env sh
# Download & install Burp Suite certificate
wget -q http://burp:8080/cert -O cert.der
openssl x509 -in cert.der -inform DER -out cert.pem
mkdir /usr/local/share/ca-certificates/extra
cp cert.pem /usr/local/share/ca-certificates/extra/cert.crt
update-ca-certificates
rm cert.der cert.pem
5) Redirect all requests received by listener to my host
6) Replace all occurrences of *api.wordpress.org* to my host
You can see the final script here: https://github.com/vavkamil/wp2burp
After that, I could see that when the websites is checking if there are any updates available, it issues the following request:
POST /plugins/update-check/1.1/ HTTP/2
Host: api.wordpress.org
User-Agent: WordPress/5.3; http://127.0.0.1:31337/
Accept: */*
Accept-Encoding: gzip, deflate
Referer: https://api.wordpress.org/plugins/update-check/1.1/
Connection: close
Content-Length: 1778
Content-Type: application/x-www-form-urlencoded
Expect: 100-continue
plugins={...}
Where the JSON data contains a list of all installed plugins, e.g.:
{
"akismet\/akismet.php":{
"Name":"Akismet Anti-Spam",
"PluginURI":"https:\/\/akismet.com\/",
"Version":"4.1.3",
"Description":"Used by millions, Akismet is quite possibly the best way in the world to <strong>protect your blog from spam<\/strong>. It keeps your site protected even while you sleep. To get started: activate the Akismet plugin and then go to your Akismet Settings page to set up your API key.",
"Author":"Automattic",
"AuthorURI":"https:\/\/automattic.com\/wordpress-plugins\/",
"TextDomain":"akismet",
"DomainPath":"",
"Network":false,
"RequiresWP":"",
"RequiresPHP":"",
"Title":"Akismet Anti-Spam",
"AuthorName":"Automattic"
},
If there is a new version available, the websites received the following response:
HTTP/2 200 OK
Date: Sun, 10 Oct 2021 19:13:57 GMT
Content-Type: application/json
Access-Control-Allow-Origin: *
Cf-Cache-Status: DYNAMIC
Expect-Ct: max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/expect-ct"
Report-To: {"endpoints":[{"url":"https:\/\/a.nel.cloudflare.com\/report\/v3?s=NpTdm3rT6Twj%2FvltPnM2Lb627HEIH4tcXE%2FTqUW0ZSqB7QQlDef1ttcmizy5cx2qcGwpKR%2BmudmYA0tp0G5QVEJ8G4%2Fu%2Bh07GKDQfbBYlJext3lDiKXRNB0EHIi3lD35oLk%3D"}],"group":"cf-nel","max_age":604800}
Nel: {"success_fraction":0,"report_to":"cf-nel","max_age":604800}
Server: cloudflare
Cf-Ray: 69c22b4018442794-PRG
Alt-Svc: h3=":443"; ma=86400, h3-29=":443"; ma=86400, h3-28=":443"; ma=86400, h3-27=":443"; ma=86400
{"plugins":{"akismet\/akismet.php":{"new_version":"4.2.1","package":"https:\/\/downloads.wordpress.org\/plugin\/akismet.4.2.1.zip"}}}
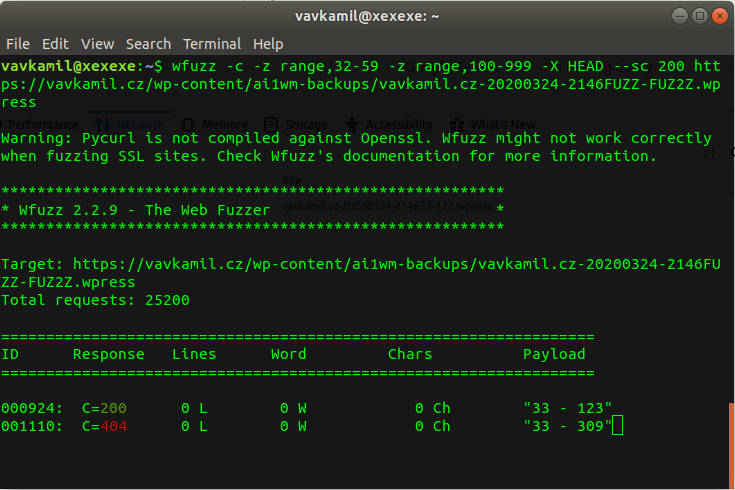
If you click on the update button, WordPress deletes the contents of the old plugin directory, and the .zip file containing a new version is downloaded and unzipped, effectively replacing all the files. Ethically exploiting this is tricky because, with any Proof of Concept, you will break the website.
But using the docker container to intercept and simulate the attack might be enough, as you can modify the response, so it will contain any version & remote zip file you want:
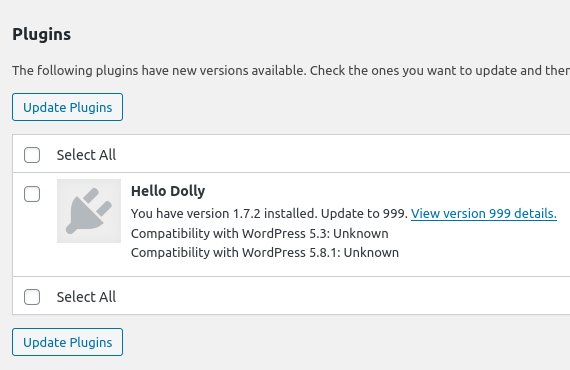
Publishing WordPress plugin PoC
I didn’t want to claim anyone’s plugin, as the update would inadvertently break the website (old plugin files will get deleted). Still, I had to simulate the attack to confirm that it works.
Fortunately for me, I already wrote a simple WP plugin two years ago, “XML-RPC Settings” to understand how the various “xmlrpc.php” attack vectors work and how to defend against them. I never bothered to upload it to WordPress Plugin Directory, but there was a possibility that someone installed it from my GitHub. For example, it was on this blog before I migrated to GitHub pages. To be sure, I installed the plugin on six different websites a while ago when I was thinking about starting this research.
After reading WordPress developer guidelines and updating the readme, I submitted the plugin for review. The exact timeline was:
- October 3rd, 2021
- Successful Plugin Submission
- October 5th, 2021
- Review in Progress, issues with plugin code (wrong stable version tag, not unique enough function names)
- October 5th, 2021
- Fixed the version and asked for another review
- October 7th, 2021
- Your review has been successfully completed.
- October 7th, 2021
- Congratulations, the plugin hosting request for XML-RPC Settings has been approved.
One hour after the plugin was approved, I was granted commit access to your Subversion (SVN) repository and uploaded my plugin:
$ sudo apt-get install subversion
$ svn co https://plugins.svn.wordpress.org/xml-rpc-settings wordpress/
$ cp xml-rpc-settings/* wordpress/.
$ cd wordpress
$ svn add trunk/*
$ svn ci -m 'feat(xml-rpc-settings): Add plugin files'
Like that, I released the plugin; now, I had to wait until the WordPress Plugin Directory synced with SVN. After a while, I noticed a Wordfence Slack notification, telling me that it found a problem on a couple of websites and a new plugin update is available; bingo!
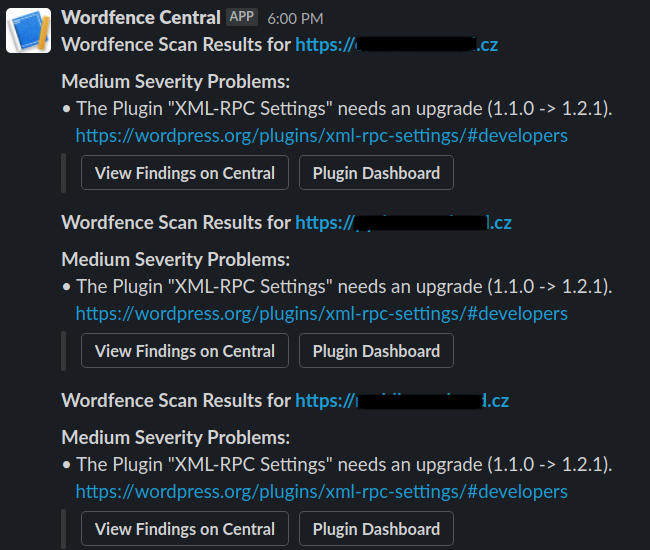
I was able to hijack a plugin installed on a couple of websites. Although there isn’t any backdoor, actually you can check the plugin:
https://wordpress.org/plugins/xml-rpc-settings
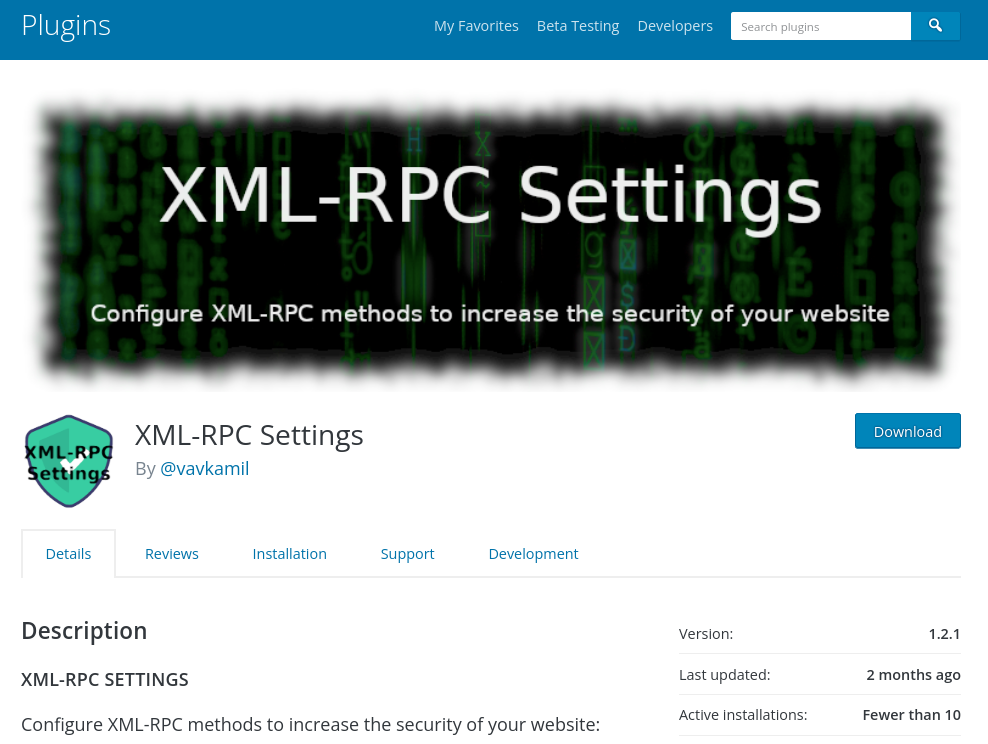
On the other hand, an attacker could now have a foothold into the website. Even worse, if the website admin enables automatic plugins updates, introduced in WordPress 5.5. That would allow the attacker to change plugin files anytime they wanted, without any user interaction.
How to defend yourself
As this is essentially vulnerable by design, I wouldn’t expect the fix from the WordPress side. If you are a big enough company, you can contact them and get your trademark in the $trademarked_slugs list. Since uploading a “dummy” plugin to the registry is not allowed, one must find another way. You can follow a couple of recommendations to keep your site secured.
Protecting themes
The theme slug is the name of the theme in lower case, with spaces replaced by a hyphen (-). It is also the folder name for the theme. The themes team can decline themes based on the name and request that the name is changed if they decide that the name is inappropriate or too similar to an existing theme or brand.
- Theme names must not use: WordPress, Theme, Twenty*
- Spell “WordPress” correctly in all public-facing text: all one word, with both an uppercase W and P
- No violation of trademarks.
That means that you can rename your custom theme in the following way: theme-internal_name to be on the safe side.
Protecting plugins
WordPress 5.8, released on July 20, 2021, introduced a new “Update URI” plugin header.
This allows third-party plugins to avoid accidentally being overwritten with an update of a plugin of a similar name from the WordPress.org Plugin Directory.
It effectively gives the website maintainer an effective way to prevent the supply chain attack, as the internal plugin will never ask for updates.
The main PHP file should include the header comment Update URI: false, example:
<?php
/**
* Plugin Name: Internal Plugin
* Version: 1.0
* Update URI: false
*/
You can read the full announcement here: https://make.wordpress.org/core/2021/06/29/introducing-update-uri-plugin-header-in-wordpress-5-8/
If you can’t, for any legacy reasons, update to WordPress 5.8, and use the Update URI mitigation, you still have some options:
The plugin slug can only contain lower case alphanumeric characters and dash as a delimiter. Some of the keywords are prohibited as well, which could help us in this case. That means that you can rename your custom plugins in the following ways:
internal_plugin_nameInternalPluginNamewp-internal-plugin-name
It is also possible to leverage a hook and write a custom update function, blocking the internal WP API call and replacing it with your own, similar to how a paid plugin offers custom updates from their servers.
Some plugins do that for you, for example, Easy Updates Manager, which allows you to block updates for specific plugins.
That being said, you should always create a fresh backup and read the changelog before updating any plugins.
Bug Bounty hunting
Since I don’t have my own recon DB anymore, I dumped about 200k subdomains from Chaos (public HackerOne programs with bounties) and scanned them with httpx:
httpx -random-agent -l chaos_all_hackerone.txt -match-string "wp-content" -o httpx_wordpress.txt
That resulted in approximately 427 WordPress websites. After verifying them with the Proof of Concept wp_update_confusion.py tool, I found 13 potential targets. That is not bad, considering the [8.2 High](https://chandanbn.github.io/cvss/#CVSS:3.1/AV:N/AC:H/PR:N/UI:R/S:C/C:H/I:H/A:L) severity.
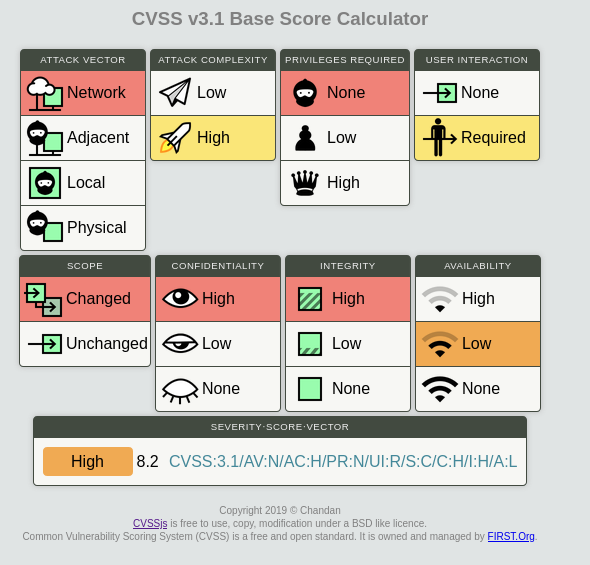
After carefully reading the policy of each bug bounty program, I found out that more than half (7) of the potential targets are out of scope. That’s a bummer, as some belong to well-known companies, and they will probably fix it anyway after I release this research.
Either way, I ended up submitting six reports. One of them is the VDP program (not offering bounties).
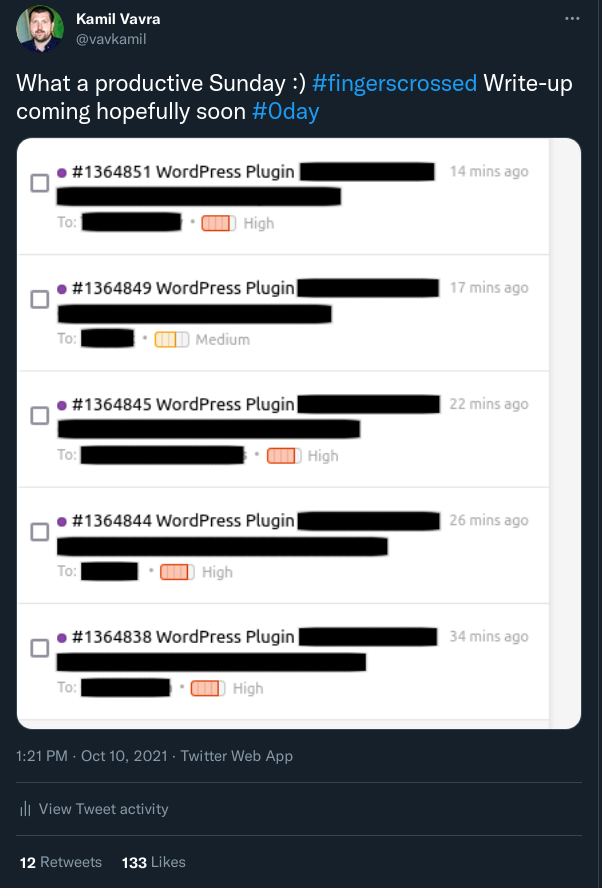
https://twitter.com/vavkamil/status/1447160385954533378
After sharing the screenshot of redacted submitted reports with a #0day hashtag on Twitter, I received a message from @naglinagli offering a collaboration. The offer was access to his extensive recon database to scan the host with my payload in exchange for splitting any future bug bounty payouts.
Since Nagli is usually in the top 5 researchers with the highest HackerOne reputation, I decided to take the offer. Mainly to see how many vulnerable websites might be there. Giving away 50% of potential bounties might be somewhat expensive, but I was pretty much done with the scan anyway.
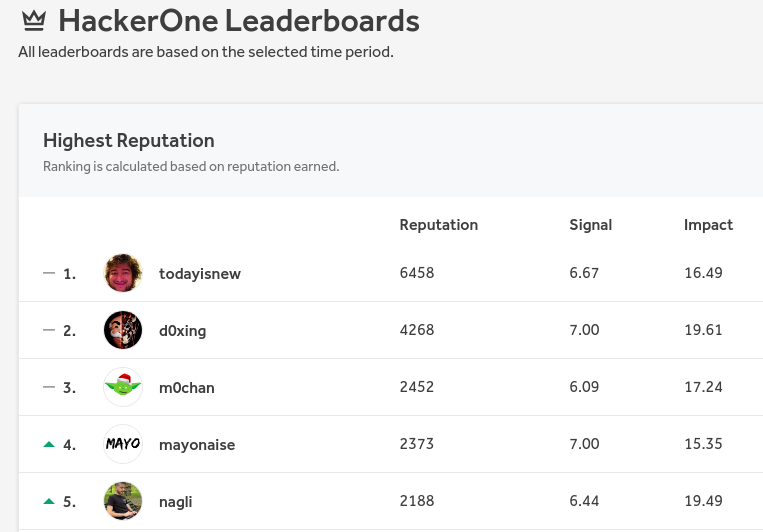
On the first try, we found more than twice as many vulnerable hosts as my previous scan attempt. I must say that the collaboration was awesome, I was impressed by how many high-profile targets he was able to find.
All in all, we submitted close the 25 reports. Unfortunately, a lot of them were closed as Informative. Some argued that their release process would not update the plugins, most likely thanks to CI/CD automation. Some didn’t understand the report, and some closed it because it was missing a clear Proof of Concept, arguing that it’s only a theoretical issue.

But others appreciated the submission, applied a fix, and one company even awarded us with a bonus for the quality of the report. You can see example of the report here: https://hackerone.com/reports/1364851
We ended up with approximately $4k in bounties, but most importantly, we made the Internet a little bit safer. It was very eye-opening how many top tech and world-known companies were potentially affected.

This research was presented as a talk at the OWASP Czech Chapter meeting on 25th November 2021.